
Commvault Auto Recovery: Introdução
A recuperação de aplicativos é um processo obrigatório para todas as organizações, independentemente de seu tamanho ou tipo de negócio, devido à necessidade de ofertas de serviços altamente disponíveis, requisitos mínimos de recuperação de perdas e suporte para infraestrutura distribuída globalmente. A pandemia da Covid-19 destacou ainda mais a importância de se ter uma estratégia de recuperação, pois as organizações enfrentam desafios sem precedentes para garantir a continuidade dos negócios. As soluções de recuperação permitem que as organizações se recuperem de forma rápida e totalmente automatizada de ataques cibernéticos, desastres e interrupções, mas as equipes de TI enfrentam desafios únicos para testar a recuperação devido à complexidade dessas soluções e às suas necessidades comerciais específicas. O Commvault Auto Recovery oferece uma solução escalável e fácil de usar para a recuperação de aplicativos. Um plano de recuperação típico pode incluir vários componentes, como replicação, armazenamento, retenção, RPOs, RTOs e automação de operações como failover, failback, testes de recuperação e análise. Esses componentes são essenciais para garantir que uma organização possa se recuperar rapidamente de um ataque cibernético ou de um desastre e retomar as operações normais.
Desafios da recuperação de aplicativos
Aumento da frequência e da sofisticação dos ataques cibernéticos:
Há um aumento no número de organizações que estão sendo afetadas por ataques de ransomware em todo o mundo. O custo incorrido por essas organizações devido a ransomware ou outros ataques cibernéticos também está aumentando exponencialmente, como pode ser visto no gráfico abaixo.
Referência: Ransomware Facts, Trends & Statistics for 2023 (safetydetectives.com)
Para se proteger contra possíveis ataques cibernéticos, é fundamental proteger os dados e as cargas de trabalho com criptografia de ponta a ponta, tanto em repouso quanto em trânsito, garantindo que os dados permaneçam confidenciais e inacessíveis a partes não autorizadas.
Mecanismos de detecção de anomalias e geração de relatórios também devem ser implementados para detectar possíveis ameaças antecipadamente e permitir a adoção de medidas proativas.
Além disso, a varredura regular das réplicas no local de recuperação de desastres para verificar se os dados não foram comprometidos ajudará a garantir que somente dados limpos sejam recuperados.
Ao implementar essas medidas, as empresas podem proteger melhor seus dados e cargas de trabalho contra o cenário de ameaças em constante evolução, mantendo a integridade e a segurança de seus sistemas.
A abordagem abrangente do Commvault Auto Recovery para proteção e recuperação de ransomware garante que seus dados estejam protegidos contra possíveis ameaças cibernéticas. A plataforma oferece uma abordagem em camadas para a segurança que permite identificar, avaliar e atenuar os riscos e, ao mesmo tempo, proteger-se contra quaisquer alterações que possam ocorrer.
Além dessas medidas, o Commvault Auto Recovery oferece integrações com ferramentas de detecção de anomalias e geração de relatórios que ajudam a detectar qualquer comportamento incomum em seu cenário de dados. A plataforma também oferece criptografia de ponta a ponta dos dados em repouso e em trânsito, garantindo que seus dados estejam protegidos contra possíveis violações.
Para garantir ainda mais a integridade dos dados, a estrutura de detecção de anomalias de tipo de arquivo da plataforma Commvault é um recurso exclusivo que permite identificar quando arquivos recém-protegidos foram corrompidos, criptografados ou contêm aplicativos maliciosos que podem estar fingindo ser arquivos “seguros”. Esse recurso ajuda as organizações a responder rapidamente a possíveis ameaças e a recuperar automaticamente versões limpas e não afetadas desses arquivos.
À medida que as ameaças cibernéticas continuam a evoluir, o Commvault Auto Recovery permanece vigilante no fornecimento de atualizações e aprimoramentos contínuos de seus recursos de segurança. A plataforma é continuamente atualizada com novas ferramentas para oferecer maior vigilância e resiliência contra essas ameaças avançadas.
Com o Commvault Auto Recovery, você pode ter certeza de que seus dados estão seguros e que pode se recuperar rapidamente no caso de um ataque de ransomware.
RPOs e RTOs agressivos:
Uma solução personalizada de proteção e recuperação de dados é necessária para atender a objetivos específicos de recuperação e evitar gastos excessivos com armazenamento ou alocação desnecessária de recursos.
Ela deve ser capaz de se adaptar às necessidades de dados em constante mudança, ajustando automaticamente a capacidade de armazenamento e fornecendo recursos de failover e failback.
Isso garante que os dados e as cargas de trabalho possam ser recuperados rapidamente, com o mínimo de interrupção dos negócios, evitando o dispendioso tempo de inatividade e reduzindo o impacto de eventos inesperados, como falhas de hardware ou desastres naturais.
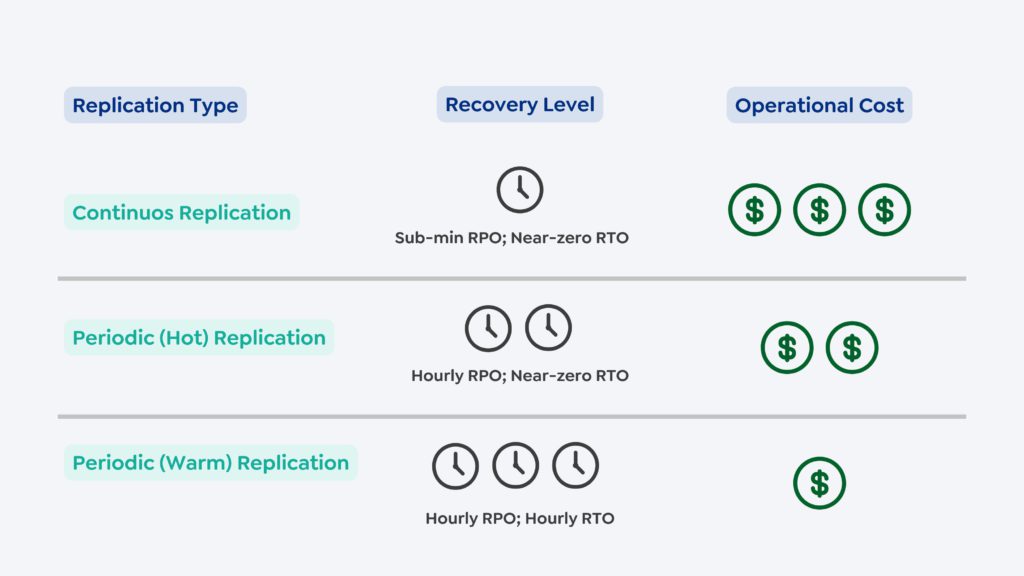
O Commvault Auto Recovery oferece várias opções para proteger e recuperar seus dados e cargas de trabalho com base em sua criticidade de missão.
Para cargas de trabalho VMware, você pode escolher entre:
- Replicação periódica (warm)
- Replicação periódica (hot)
- Replicação contínua
Essas opções permitem atingir diferentes níveis de objetivo de ponto de recuperação (RPO) e objetivo de tempo de recuperação (RTO).
Complexidade no gerenciamento da infraestrutura de recuperação e orquestração
Gerenciar a infraestrutura de recuperação e a orquestração pode ser uma tarefa complexa, especialmente ao lidar com diversos tipos de cargas de trabalho e dados que estão fora do local ou na nuvem.
O desafio se intensifica quando cada carga de trabalho ou tipo de dado exige uma interface de usuário diferente, o que pode resultar em ineficiências, erros e atrasos.
O Commvault Auto Recovery oferece uma abordagem simplificada e otimizada para a recuperação de dados em escala.
Com sua interface única, ele permite o gerenciamento fácil das necessidades de backup e disaster recovery (DR) em diferentes ambientes, como no local, em várias nuvens e em ambientes híbridos.
Sua extensa biblioteca de API possibilita uma conexão perfeita com seus dados, enquanto a interface de usuário intuitiva proporciona uma experiência fácil de usar, reduzindo a complexidade operacional.
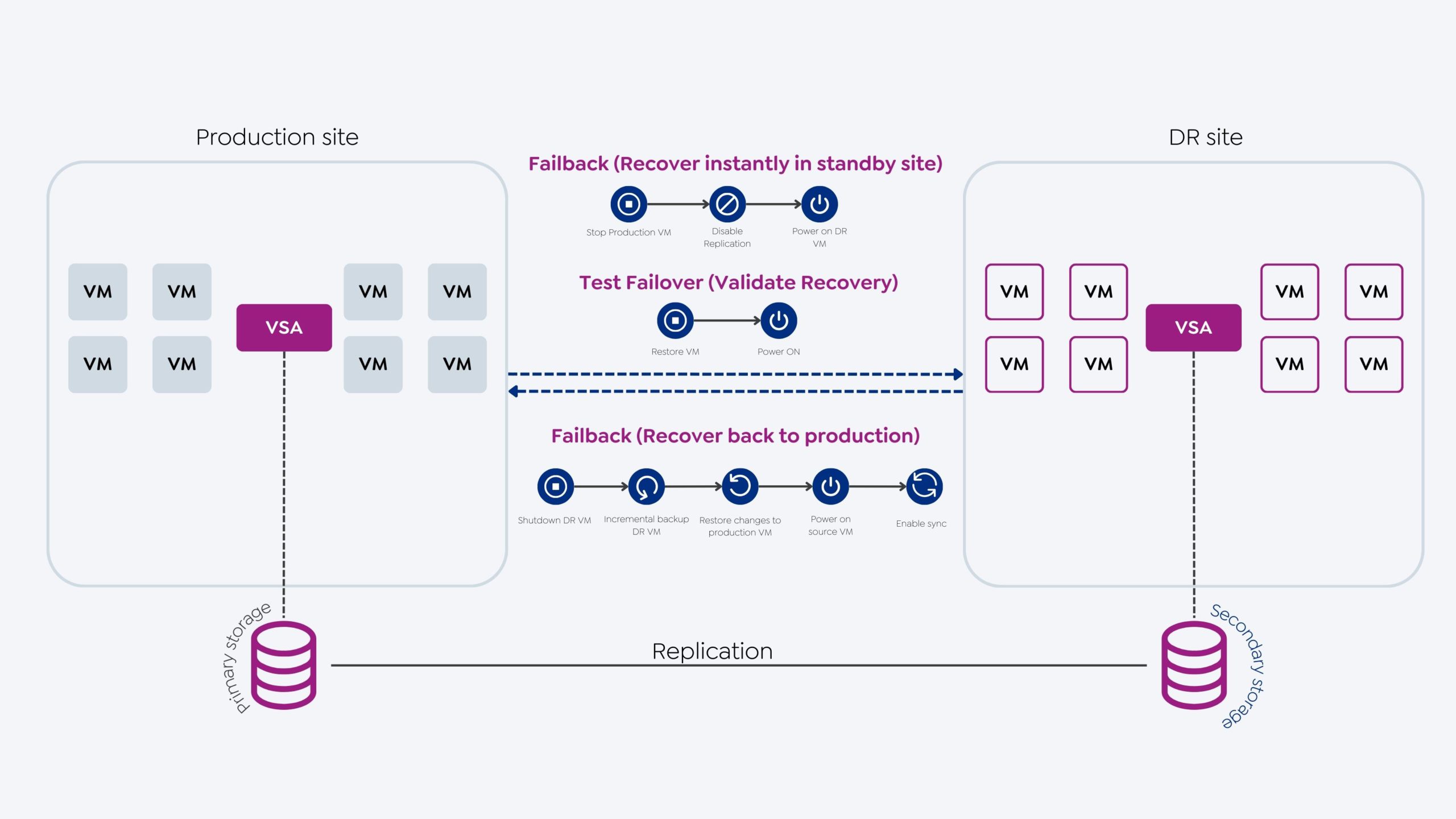
A plataforma também simplifica as operações contínuas com fluxos de trabalho pré-criados, permitindo a orquestração de failover e failback com um clique, reduzindo o tempo e o esforço necessários para recuperar dados.
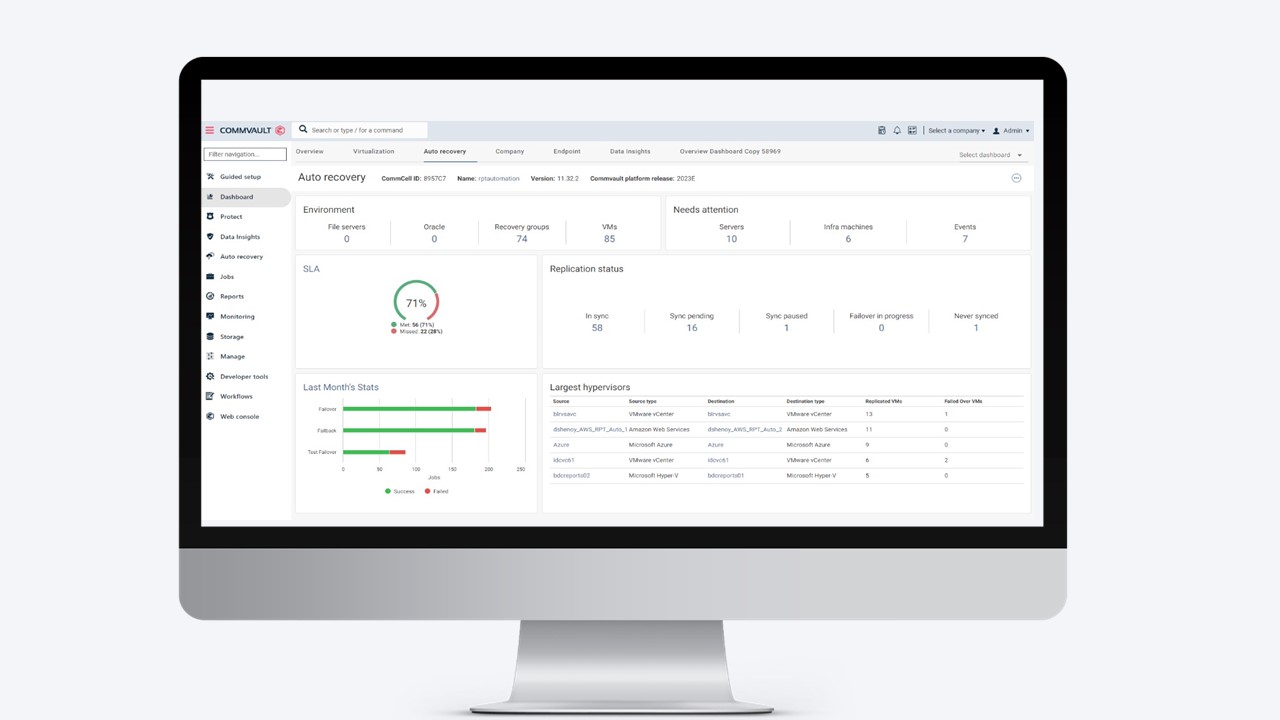
O Commvault Auto Recovery oferece um painel de controle centralizado que permite visualizar e gerenciar todos os seus recursos, independentemente do ambiente em que se encontram. Essa centralização aumenta a eficiência operacional e a agilidade, possibilitando a recuperação rápida de dados e a minimização do tempo de inatividade.
Além disso, a solução oferece controle de acesso baseado em funções, proporcionando flexibilidade administrativa. Isso inclui:
- Implantações de autoatendimento
- Suporte a ambientes multilocatário
Esses recursos facilitam o gerenciamento da recuperação de dados em escala.
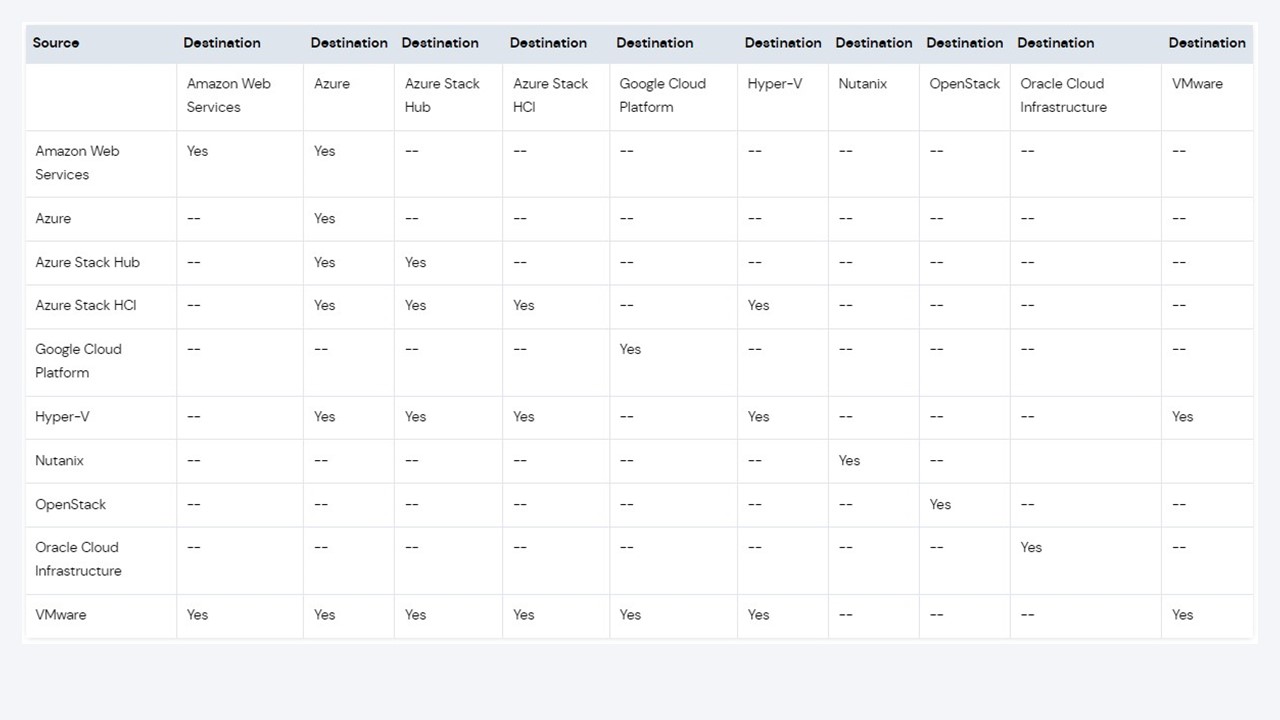
O Commvault Auto Recovery oferece suporte à recuperação de várias cargas de trabalho, como VMs, bancos de dados e arquivos/volumes, permitindo a replicação de dados:
- Do local para a nuvem
- Da nuvem para a nuvem
- Entre diferentes nuvens públicas
Por exemplo, um usuário pode replicar suas VMs VMware do local para o AWS e recuperar todo o aplicativo.
Consolidar diferentes necessidades de recuperação de desastres é um grande desafio, mas o Commvault Auto Recovery oferece uma solução abrangente para atender a todas essas demandas em uma única plataforma.
Além disso, a solução conta com uma interface web de gerenciamento intuitiva, que facilita a administração de todas as operações de recuperação de desastres.
Commvault Auto Recovery – RPO and RTO
Recovery Point Objective (RPO)
O Commvault Auto Recovery oferece opções de replicação em vários níveis, desde o armazenamento até os aplicativos executados em máquinas físicas ou virtuais.
Os dois principais tipos de replicação são:
- Replicação periódica: oferece um RPO moderado
- Replicação contínua: oferece um RPO baixo ou próximo de zero
Independentemente do tipo de replicação ou da carga de trabalho, o Commvault Auto Recovery garante:
✅ Configuração consistente
✅ Orquestração de recuperação
✅ Automação do processo
A plataforma simplifica a replicação, abstraindo complexidades e oferecendo uma interface amigável, além de APIs fáceis de usar.
Com o Commvault Auto Recovery, as necessidades de replicação e recuperação podem ser gerenciadas com perfeição em diferentes tipos de cargas de trabalho e plataformas. Seja uma replicação periódica ou contínua, a solução garante proteção e recuperação de dados confiáveis.
Além disso, a interface intuitiva e as APIs da Commvault tornam o gerenciamento de replicação e recuperação de desastres mais simples, sem necessidade de amplo conhecimento técnico ou treinamento.
A Commvault oferece uma interface de usuário e APIs simples, consistentes e intuitivas, garantindo que a configuração e orquestração de DR sejam consistentes em todos os tipos de replicação e cargas de trabalho.
Com a Commvault, você escolhe a solução de replicação que melhor atende às suas necessidades, de acordo com o seu ambiente e seus requisitos de RPO.
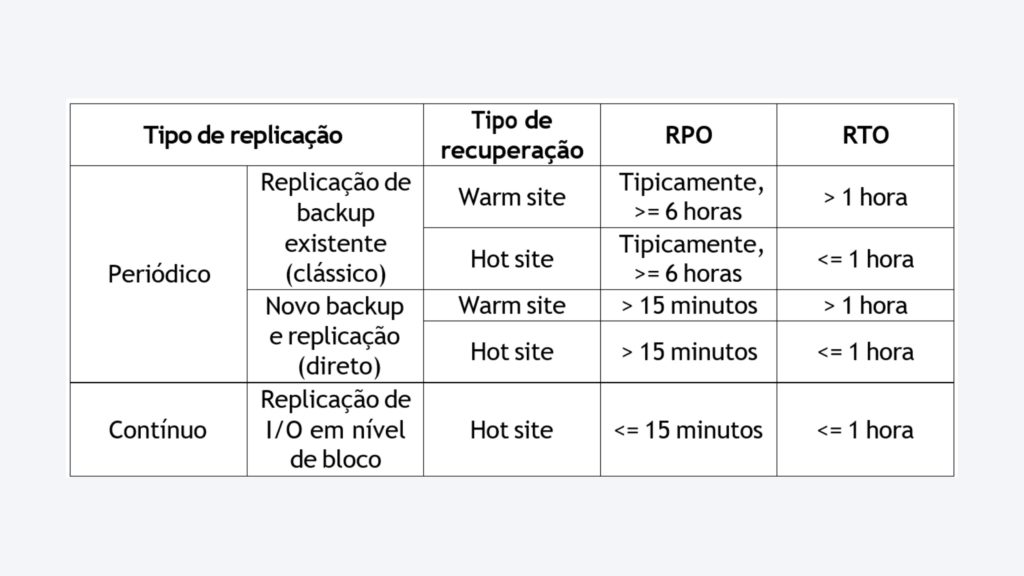
Replicação períodica
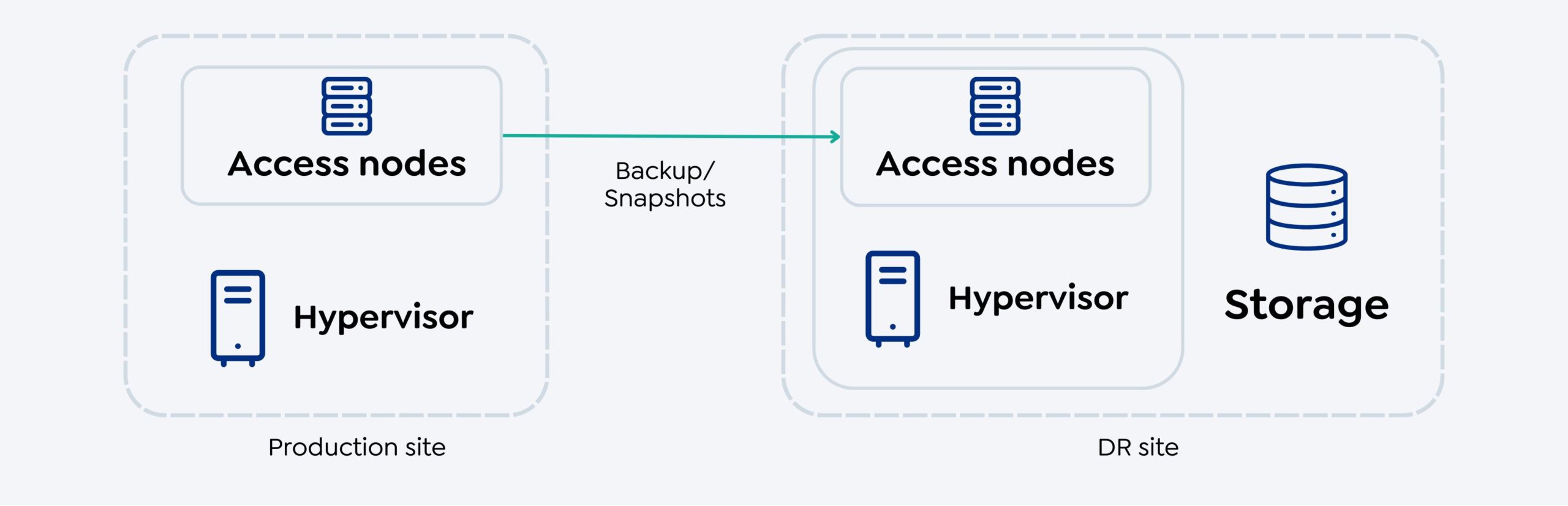
A replicação periódica é um tipo de replicação em que os dados de backup ou instantâneos são copiados de forma síncrona para o site de recuperação (site de DR) de acordo com o SLA configurado. Essa replicação pode ser feita no nível da VM, do volume ou do aplicativo, dependendo dos requisitos do usuário. A replicação periódica é útil quando sua estratégia de DR exige a proteção das cargas de trabalho com RPOs horários/diários.
Para implementar a replicação periódica, é necessário pelo menos um nó de acesso com o pacote do Virtual Server instalado no site de produção e um nó de acesso com o pacote do Virtual Server no site de DR. Esses nós de acesso se conectam ao hipervisor para ler os dados do hipervisor de origem e transferi-los para o nó de acesso de destino. O pacote MediaAgent pode ser instalado no mesmo nó de acesso no site de DR para gerenciar a transferência de dados. O MediaAgent executa a deduplicação, a compactação, a criptografia e outras tarefas dos dados. Ele transfere dados por uma rede (WAN) ou SAN para o hipervisor de destino e grava dados no site de destino.
Além dos nós de acesso e do MediaAgent, também é necessário provisionar o(s) armazenamento(s) que armazenará(ão) os dados de backup ou os instantâneos obtidos no site de produção. O armazenamento pode residir no site de produção, no site de DR ou em qualquer outro local, como a nuvem metálica. No diagrama acima, o armazenamento está no site de DR.
Para requisitos de RPO de 15 minutos ou mais, opte pela replicação periódica. Esse tipo de replicação é normalmente usado para cargas de trabalho não críticas para a missão, em que a perda de dados por alguns minutos/horas pode ser tolerada. Essa opção pode otimizar seus custos de replicação e recuperação.
Replicação contínua
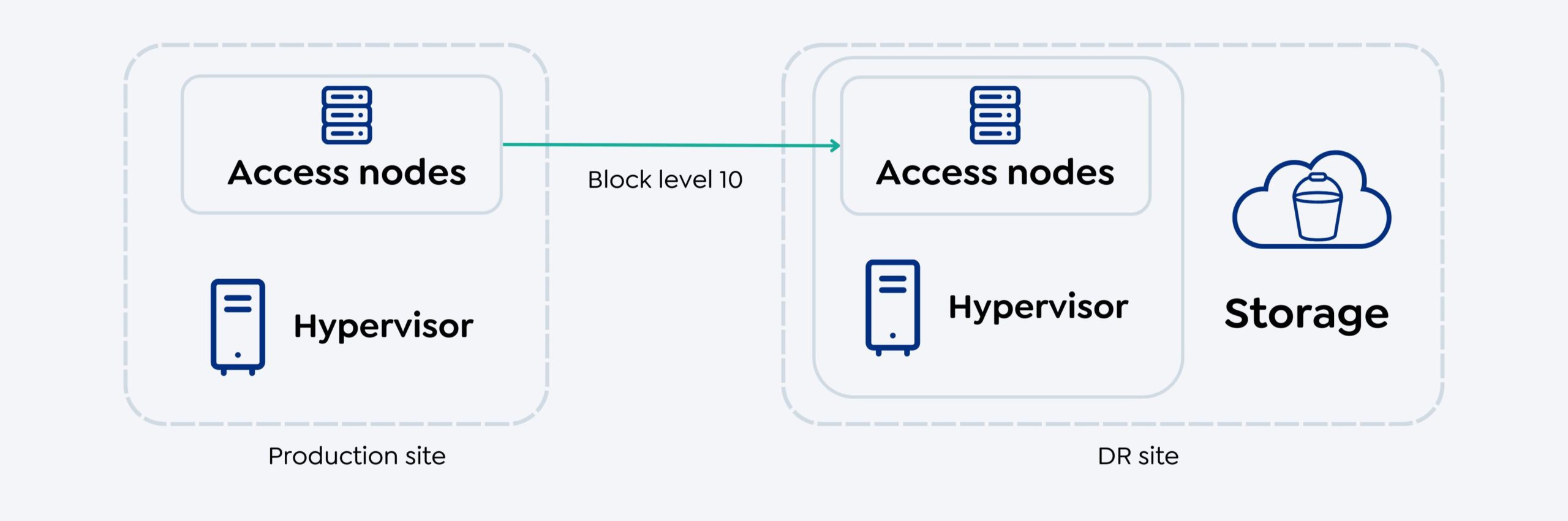
A replicação contínua é um método de replicação que oferece RPO (Recovery Point Objective, objetivo de ponto de recuperação) próximo de zero, replicando continuamente IOs (Input/Output, entrada/saída) da VM de produção para a VM de DR. Essa abordagem permite que as alterações feitas na VM de produção sejam imediatamente replicadas para a VM de DR, proporcionando o mais alto nível de consistência de dados e perda mínima de dados em caso de desastre.
Para implementar a replicação contínua, é necessário pelo menos um nó de acesso com o pacote do Virtual Server instalado no site de produção e um nó de acesso com o pacote do Virtual Server no site de DR. Esses nós de acesso se conectam ao hipervisor para ler os dados do hipervisor de origem e transferi-los para o nó de acesso de destino.
Além disso, é necessário provisionar o armazenamento para o RP Store, que armazenará os pontos de recuperação necessários para restaurar a VM durante o failover e o failover de teste. O armazenamento de RP precisa estar localizado no site de DR ou próximo a ele para acelerar a restauração da VM.
A replicação contínua oferece vários benefícios, como baixo RPO, tempo de recuperação rápido e melhor consistência dos dados. É uma solução ideal para cargas de trabalho de missão crítica que exigem altos níveis de disponibilidade e perda mínima de dados.
Recovery Time Objective/Recovery Type (RTO)
O Commvault Auto Recovery oferece aos clientes flexibilidade no que diz respeito às opções de recuperação. Há suporte para dois tipos de recuperação: warm site e hot site.
Warm site recovery
Quando for possível tolerar um tempo de inatividade um pouco maior e desejar reduzir os custos de replicação e recuperação, use o warm site recovery, disponível a partir da versão 11.28 do Commvault Auto Recovery. Na warm site recovery, a VM e os discos não são implantados durante a criação inicial do grupo de replicação; em vez disso, eles são implantados durante o failover. Durante a replicação, somente os dados são replicados para o site de DR, o que proporciona uma possível redução nos custos de recuperação para cargas de trabalho que não são críticas para a missão, em que tempos de inatividade mais altos podem ser tolerados.
Como as VMs e os discos são criados durante o failover, o tempo necessário para fazer o failover das VMs do site de produção para o site de DR será superior a uma hora na maioria dos cenários.
Hot site recovery
Quando for necessário um tempo de inatividade muito baixo (RTO próximo de zero), para cargas de trabalho essenciais, use a recuperação de hot site. A recuperação hot site implementa a VM e os discos no site de DR durante a replicação inicial e a replicação subsequente atualizará os dados no armazenamento. Como a VM e os discos são implantados e mantidos durante a replicação, isso acarreta custos potencialmente mais altos; no entanto, o failover das cargas de trabalho de produção para o site de DR ocorre em poucos minutos.
O ransomware é um tipo de malware que criptografa os dados da vítima e exige pagamento para sua descriptografia. Veja a seguir as etapas típicas envolvidas na recuperação de ransomware:
Validação de recuperação
A primeira etapa da recuperação de ransomware é validar os backups/pontos de recuperação. Isso envolve a verificação da integridade dos backups para garantir que eles não estejam infectados com ransomware. Além disso, é importante validar a prontidão de recuperação dos sistemas e procedimentos da organização para garantir que eles possam restaurar os sistemas e os dados ao seu estado anterior.
Recuperação forense
A próxima etapa é realizar uma análise forense do ataque de ransomware. Isso envolve a investigação de como o ataque ocorreu e a identificação da extensão dos danos. A análise forense é importante para determinar como o ransomware conseguiu se infiltrar nos sistemas da organização e para evitar futuros ataques.
Orquestração de recuperação
O processo de recuperação envolve a restauração dos sistemas e dos dados ao seu estado anterior. O processo de recuperação pode ser dividido em duas fases: recuperação de cargas de trabalho limpas em escala e recuperação da infraestrutura de backup e recuperação de desastres (DR) em um ambiente de espera.
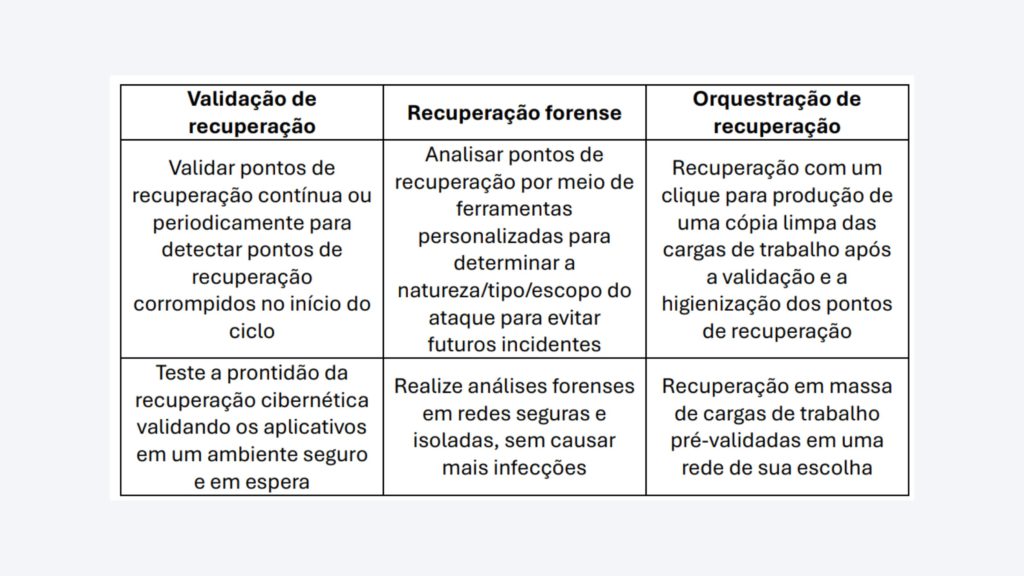
Validação de recuperação
Métodos de validação
Validação de Pontos de Recuperação
Ao validar os pontos de recuperação, é importante realizar uma análise completa das ameaças para garantir que os backups não estejam infectados com ransomware ou outros tipos de malwares. Isso pode ser feito usando ferramentas integradas, como o Microsoft Defender, ou ferramentas de terceiros que ofereçam suporte à integração com outras ferramentas de segurança.
Ferramentas integradas de análise de ameaças, como o Microsoft Defender, podem examinar os pontos de recuperação em busca de malware e outras ameaças, ajudando a identificar qualquer infecção antes que os backups sejam usados para recuperação. Essas ferramentas também podem ajudar a identificar possíveis vulnerabilidades no processo de backup, como métodos inseguros de armazenamento ou transferência, que talvez precisem ser corrigidos para evitar futuras infecções.
Frequência de Validação
Quando se trata de validar pontos de recuperação para a recuperação de ransomware, as organizações têm algumas opções diferentes quanto à frequência de realização dessas verificações.
-
Validação Completa: A abordagem de validar todos os pontos de recuperação envolve realizar uma análise completa de cada backup para garantir que estejam livres de malware ou outras ameaças. Essa abordagem pode ser demorada e exigir muitos recursos, mas oferece o mais alto nível de garantia de que os backups estão limpos e podem ser usados para recuperação.
-
Verificações Pontuais: Outra abordagem é realizar verificações pontuais, onde uma amostra de backups é selecionada e validada periodicamente. Essa abordagem consome menos recursos, mas apresenta algum risco de que um backup comprometido possa não ser detectado se não for incluído na amostra.
Teste da Prontidão de Recuperação dos Aplicativos
Para garantir que os aplicativos possam ser recuperados no caso de um desastre ou ataque de ransomware, é importante testar a prontidão de recuperação dos aplicativos. Isso pode ser feito testando a recuperação de cargas de trabalho e realizando simulações de incêndio para ajudar a garantir que os aplicativos estejam em conformidade com os contratos de nível de serviço de recuperação.
Usando o Commvault Auto Recovery, você pode validar os pontos de recuperação de máquinas virtuais executando varreduras do Windows Defender ou outras ferramentas de varredura e validação de terceiros nos pontos de recuperação periodicamente. Além disso, é possível testar a prontidão da recuperação para garantir que todas as ações personalizadas por meio de scripts pré e pós sejam executadas conforme o esperado, cumprindo assim os SLAs de recuperação.
Recuperação Forense
Uma solução de recuperação deve permitir que as equipes de operações de segurança analisem os ataques cibernéticos para identificar o vetor de ataque e o escopo do ataque, implementando medidas que possam evitar ataques futuros. O Commvault Auto Recovery oferece uma solução robusta e integrada para ajudar as organizações não apenas a prevenir e se recuperar de ataques de ransomware, mas também fornecer às equipes de operações de segurança a capacidade de analisar esses ataques em um ambiente isolado, longe dos servidores de produção.
Com o Commvault Auto Recovery, as organizações podem:
- Teste o failover/recuperação de cargas de trabalho e dados infectados em um ambiente isolado sem acesso à rede para permitir que as equipes de segurança façam login nessas cargas de trabalho e analisem o ataque sem afetar os sistemas de produção.
- Integrar com ferramentas forenses para determinar a natureza, o tipo e o escopo do ataque e ajudar a evitar futuros incidentes.
- Acesse APIs para todas as operações de orquestração de recuperação para automatizar as operações e integrá-las aos sistemas SOAR.
- Use a funcionalidade de pré e pós-script para testar operações de failover, permitindo a automação da ferramenta forense personalizada durante a fase de análise forense.
Com esses recursos, o Commvault Auto Recovery permite que as organizações se recuperem rapidamente de ataques de ransomware e minimizem o impacto em suas operações. Ao aproveitar a nossa solução, as organizações podem ter a tranquilidade de saber que estão bem preparadas para qualquer incidente relacionado a ransomware que possa ocorrer.
Commvault Auto Recovery – Orquestração de Recuperação
Um dos principais benefícios do Commvault Auto Recovery é sua escalabilidade e orquestração de recuperação com um clique, o que permite que as empresas recuperem muitas cargas de trabalho rapidamente, sem comprometer os objetivos de tempo de recuperação. As organizações podem restaurar as cargas de trabalho para a produção com facilidade usando pontos de recuperação higienizados e recuperar cargas de trabalho críticas dentro dos objetivos de tempo de recuperação definidos, reduzindo o risco de tempo de inatividade prolongado dos negócios.
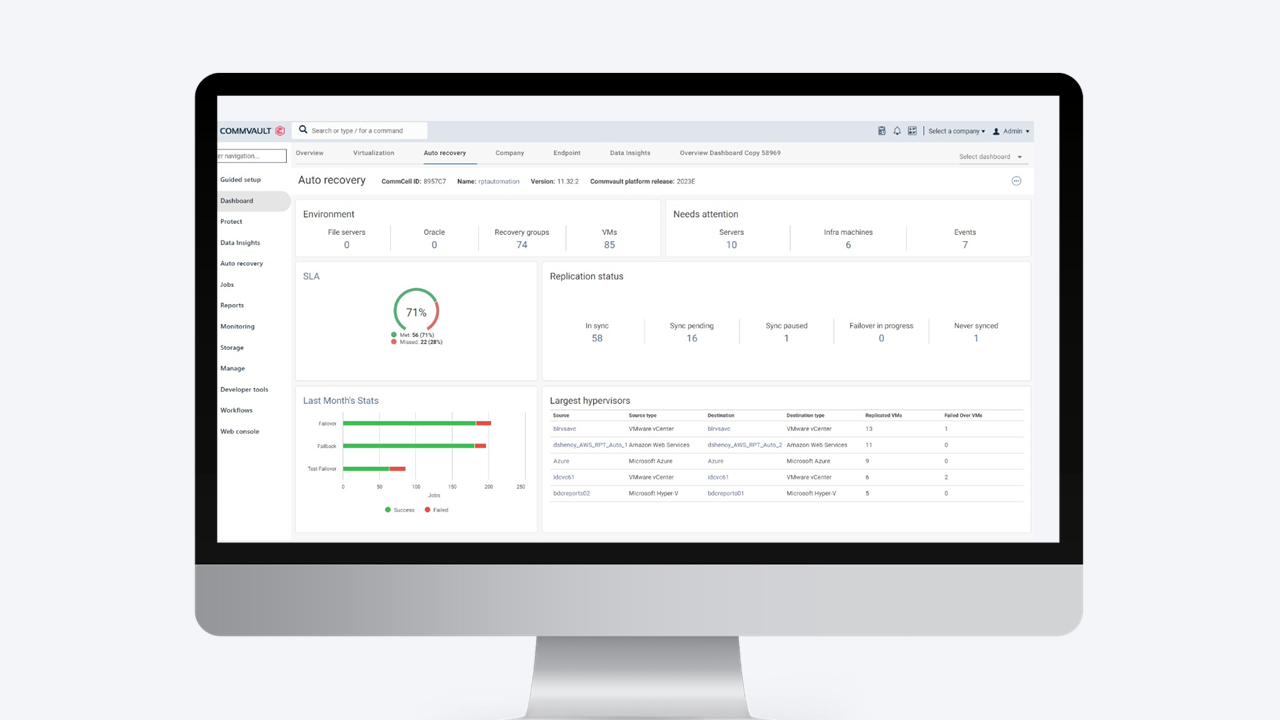
Command Center
O Commvault Command Center é uma interface de usuário baseada na Web altamente personalizável, projetada para gerenciar com facilidade suas iniciativas de proteção de dados e recuperação de desastres. Ela pode ser usada para várias finalidades, como configurar backups e restaurações, definir políticas de proteção de dados, agendar tarefas, monitorar operações, criar relatórios e muito mais.
O Commvault Command Center consolida informações e funcionalidades essenciais para ajudar a simplificar a administração de sua estratégia geral de proteção de dados, fornecendo um painel unificado de proteção de dados para análises, relatórios e muito mais.
Recovery Groups
Os Recovery Groups (Grupos de Recuperação) são um agrupamento lógico de servidores relacionados que precisam ser replicados e/ou recuperados juntos. É possível criar grupos de recuperação usando a interface de usuário intuitiva, o Command Center ou as APIs. Com a ajuda desses grupos de recuperação, é possível recuperar em massa e fazer failover de um aplicativo ou agrupar aplicativos de forma descomplicada. Além disso, você pode definir a prioridade de cada servidor para determinar a ordem em que os servidores devem ser recuperados.
Operações de Recuperação
O Commvault Auto Recovery automatiza todo o processo de recuperação de aplicativos, fornecendo operações de recuperação orquestradas com um clique, como failover, teste de failover, failback e desfazer failover.
Planned Failover (Failover Planejado)
 O planned failover (failover planejado) é um processo de transição intencional de uma carga de trabalho de produção de seu site principal para um site secundário ou de recuperação de desastres (DR) de forma controlada. Esse procedimento é normalmente usado em situações em que o site de produção está ficando off-line para manutenção, atualizações ou outros eventos planejados, sendo essencial manter a disponibilidade do serviço ativando rapidamente um site de DR.
O planned failover (failover planejado) é um processo de transição intencional de uma carga de trabalho de produção de seu site principal para um site secundário ou de recuperação de desastres (DR) de forma controlada. Esse procedimento é normalmente usado em situações em que o site de produção está ficando off-line para manutenção, atualizações ou outros eventos planejados, sendo essencial manter a disponibilidade do serviço ativando rapidamente um site de DR.
Etapas do Failover Planejado
-
Desliga a VM de produção: A primeira etapa de um failover planejado é desligar a máquina virtual (VM) de produção. Essa ação garante que as alterações ocorridas durante o failover planejado não sejam perdidas ou corrompidas.
-
Cria backup/snapshot incremental: A próxima etapa é criar um backup ou snapshot incremental da VM de produção. Esse backup ou snapshot captura todas as alterações que ocorreram desde o último backup completo ou snapshot.
-
Replica os dados incrementais: Em seguida, os dados incrementais são replicados para o site de DR, caso a replicação esteja ativada. Essa etapa garante que o site de DR tenha os dados mais recentes necessários para o failover.
-
Desativa a replicação: Depois que os dados incrementais forem replicados para o site de DR, a replicação do site de produção para o site de DR deverá ser desativada. Essa ação evita que as alterações feitas durante o failover planejado sejam perdidas ou corrompidas.
-
Liga a VM de DR: Por fim, a VM de DR deve ser ligada e os serviços devem ser iniciados para concluir o failover planejado.
Unplanned failover
Unplanned Failover (Failover Não Planejado)
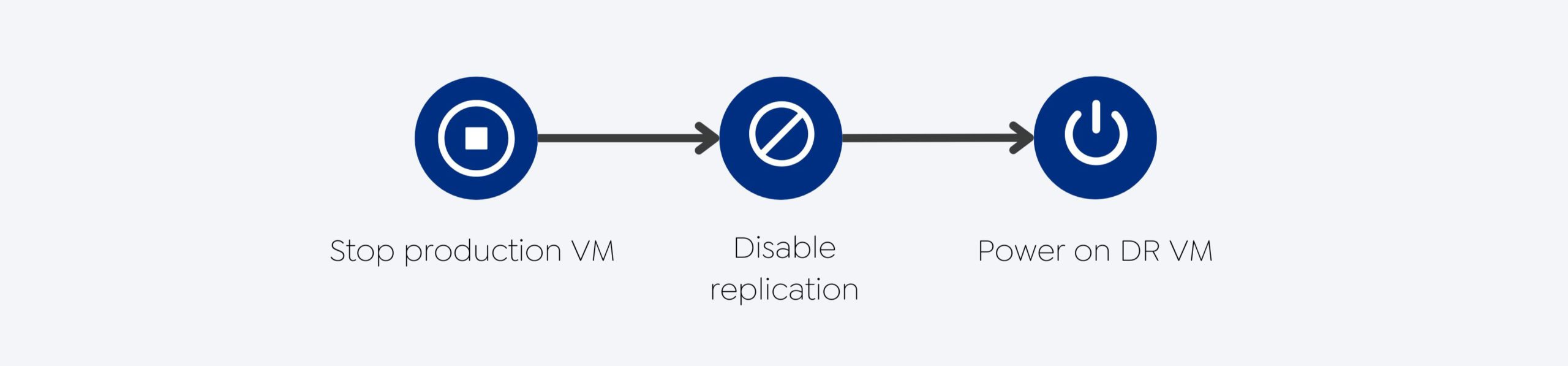
O unplanned failover (failover não planejado) é um procedimento de transição de uma carga de trabalho de produção de seu site principal para um site secundário ou de recuperação de desastres (DR) devido a um evento inesperado que causa uma interrupção no ambiente de produção.
Normalmente, esse procedimento é utilizado quando os aplicativos de produção (ou o site de produção) ficam indisponíveis devido a um ataque cibernético, falha de hardware, desastre natural ou queda de energia.
Etapas do Failover Não Planejado
-
Desliga a VM de produção: A primeira etapa de um failover não planejado é desligar a máquina virtual (VM) de produção. Essa ação é necessária para evitar qualquer perda ou corrupção de dados durante o processo de failover.
-
Desativa a replicação do site de produção para o site de DR: Após desligar a VM de produção, a replicação do site de produção para o site de DR deve ser desativada. Isso garante que as alterações feitas durante o failover não planejado não sejam perdidas ou corrompidas.
-
Liga a VM de DR: Depois que a consistência dos dados for verificada, a VM de DR deve ser ligada e os serviços devem ser iniciados para retomar as operações. A VM de DR assume a carga de trabalho da VM de produção, garantindo a continuidade do serviço até que o site de produção esteja novamente on-line.
Restauração do Site de Produção
Depois que o site de DR estiver operacional, devem ser feitos esforços para restaurar o site de produção ao seu estado original. Isso pode envolver:
- O reparo ou substituição de qualquer hardware com falha;
- A restauração de dados a partir de backups;
- Outras medidas para colocar o site de produção novamente on-line;
Test failover/recovery
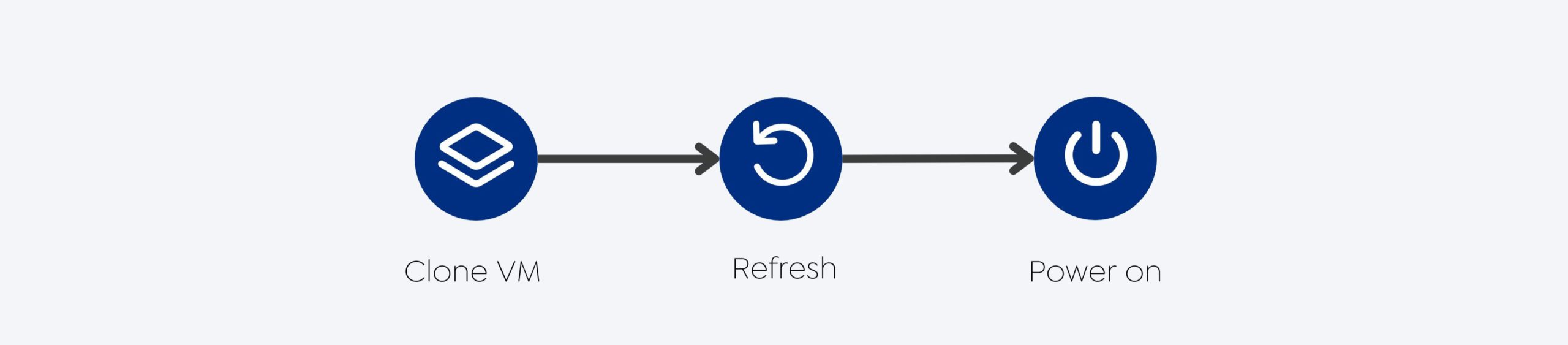 O test failover (failover de teste) é um procedimento de validação da prontidão de recuperação e dos SLAs de recuperação, por meio da simulação de um cenário de failover em um ambiente de espera controlado.
O test failover (failover de teste) é um procedimento de validação da prontidão de recuperação e dos SLAs de recuperação, por meio da simulação de um cenário de failover em um ambiente de espera controlado.
Etapas do Failover de Teste
-
Restaura a VM DR em uma rede de sua escolha: A primeira etapa de um failover de teste é restaurar a VM DR em uma rede específica. Essa rede pode ser isolada do ambiente de produção para evitar qualquer impacto na carga de trabalho ativa.
-
Liga a VM DR: Depois de restaurar a VM DR, a próxima etapa é ligá-la e garantir que ela possa iniciar os serviços e aplicativos necessários. Essa etapa valida a prontidão da VM DR para assumir a carga de trabalho do ambiente de produção, se necessário.
-
Limpa VMs de teste: Quando o prazo de validade das VMs de teste é atingido, elas são limpas automaticamente, sem necessidade de intervenção do usuário.
Failback

O failback é um procedimento de transição de uma carga de trabalho de produção do site de recuperação de desastres (DR) de volta ao site principal, após um evento de failover. Normalmente, o failback é realizado quando o site principal está novamente on-line e totalmente operacional.
Etapas do Failback
-
Desliga a VM de DR: A primeira etapa é desligar a VM de DR, que estava executando a carga de trabalho de produção durante o evento de failover.
-
Cria backup incremental/snapshot da VM DR: Após desligar a VM DR, deve-se criar um backup incremental ou um snapshot. Esse backup captura todas as alterações feitas na VM durante o evento de failover.
-
Replica os dados incrementais para o site de produção: Depois de criar o backup/snapshot, todos os dados incrementais gerados no site de DR durante o failover devem ser replicados de volta para o site de produção. Isso garante que nenhuma alteração seja perdida ou corrompida.
-
Liga a VM de origem: Após a conclusão da replicação, a carga de trabalho de produção pode ser ligada e retomada no site principal.
-
Reativa a replicação do site de produção para o site de DR: Depois que a VM de origem estiver operacional, a replicação do site de produção para o site de DR deve ser reativada. Isso garante que o site de DR continue atualizado e pronto para assumir a carga de trabalho em caso de uma nova interrupção ou desastre.
Objetivo do Failback
O objetivo do failback é fazer a transição da carga de trabalho de volta ao site principal, garantindo a consistência dos dados e minimizando qualquer impacto na disponibilidade do serviço.
Undo Failover (Desfazer Failover)
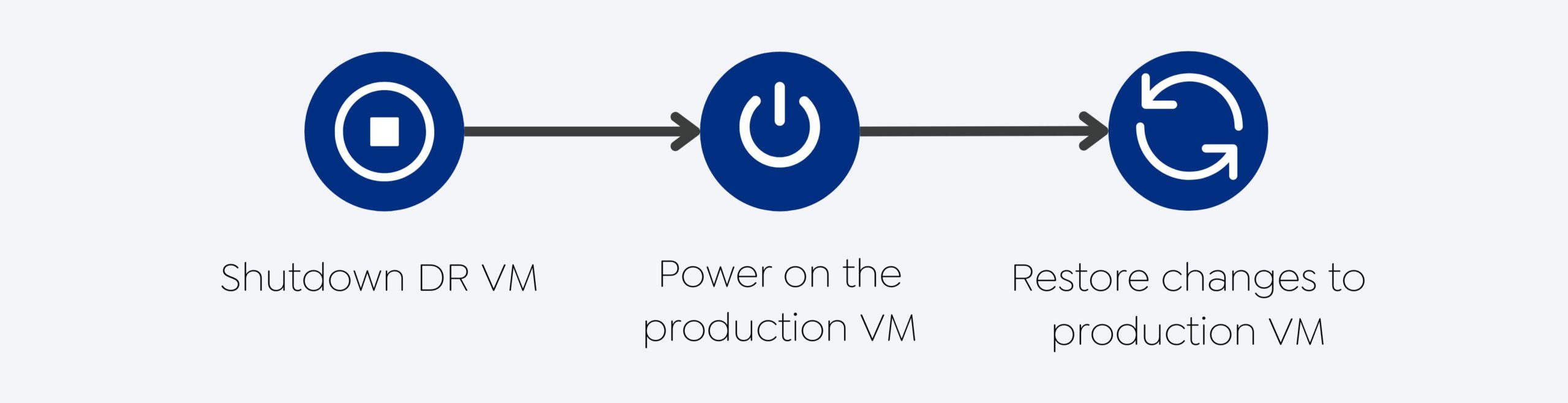 O undo failover é um procedimento para reverterum evento de failover e fazer a transição da carga de trabalho de produção de volta para o site principal. Esse procedimento é normalmente executado quando o failover foi iniciado por engano ou se os servidores restaurados estiverem corrompidos, sendo necessário reverter a operação.
O undo failover é um procedimento para reverterum evento de failover e fazer a transição da carga de trabalho de produção de volta para o site principal. Esse procedimento é normalmente executado quando o failover foi iniciado por engano ou se os servidores restaurados estiverem corrompidos, sendo necessário reverter a operação.
Etapas do Undo Failover
-
Desliga a VM DR: A primeira etapa é desligar a VM de DR, que estava executando a carga de trabalho de produção durante o evento de failover.
-
Descarta as alterações na VM DR: Após desligar a VM DR, todas as alterações feitas durante o evento de failover devem ser descartadas. Isso garante que o site principal possa retomar as operações sem inconsistências ou corrupção de dados.
-
Liga a VM de origem: Depois que as alterações forem descartadas, a VM de origem pode ser ligada e iniciada. Os serviços devem ser reiniciados para retomar as operações no site principal.
-
Reativa a replicação do site de produção para o site de DR: Após a validação do site principal, a replicação do site de produção para o site de DR deve ser reativada para garantir a continuidade da proteção dos dados.
Objetivo do Undo Failover
O objetivo do undo failover é fazer a transição da carga de trabalho de volta ao site principal sem replicar os dados do site de DR para o site de produção, garantindo um ambiente consistente e confiável.


